다음은 예제는 스팸 문장을 이용해서 결정트리를 만들어 낸다.
import numpy as np
import matplotlib.pyplot as plt
from matplotlib import font_manager, rc
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.tree import DecisionTreeClassifier, plot_tree
from sklearn.model_selection import train_test_split
# Set up Korean font for matplotlib
font_path = "c:/Windows/Fonts/malgun.ttf" # Windows의 경우
font_name = font_manager.FontProperties(fname=font_path).get_name()
rc('font', family=font_name)
# Sample spam dataset
data = [
("지금 무료 돈!!!", "spam"),
("안녕하세요, 잘 지내시나요?", "ham"),
("무료 아이폰을 받으세요", "spam"),
("내일 만날까요?", "ham"),
("축하합니다, 당첨되셨습니다!", "spam"),
("회의 가능하신가요?", "ham"),
("무료 상품을 받으세요", "spam"),
("약속을 변경할 수 있을까요?", "ham"),
("이 이메일에 회신하여 상품을 받으세요", "spam"),
("오후 3시에 회의", "ham"),
("당첨자로 선정되었습니다", "spam"),
("만나서 반가워요", "ham"),
("무료 선물을 받으세요", "spam"),
("지금 만날 수 있나요?", "ham"),
("현금을 받으려면 회신하세요", "spam"),
("카페에서 만나요", "ham"),
("현금 상금을 받으셨습니다", "spam"),
("내일 시간 되시나요?", "ham"),
("지금 무료 돈 받기", "spam"),
("내일 점심 같이 하실래요?", "ham")
]
# Split the data into texts and labels
texts, labels = zip(*data)
# Convert labels to binary values
labels = np.array([1 if label == "spam" else 0 for label in labels])
# Vectorize the text data using CountVectorizer
vectorizer = CountVectorizer()
X = vectorizer.fit_transform(texts)
# Split the dataset into training and testing sets
X_train, X_test, y_train, y_test = train_test_split(X, labels, test_size=0.3, random_state=42)
# Train a decision tree classifier
clf = DecisionTreeClassifier()
clf.fit(X_train, y_train)
# Plot the decision tree
plt.figure(figsize=(20,10))
plot_tree(clf, filled=True, feature_names=vectorizer.get_feature_names_out(), class_names=["ham", "spam"])
plt.show()여기에서 문장을 학습할지 단어 단위로 학습할지는, CountVectorizer(단어 출연 빈도가 높을 수로 높은 가중치) TfidfVectorizer(등장율이 낮을 수도 높은 가중치)으로 조정할 수 있다.
1: "Free money now"
2: "Free iPhone now"
CountVectorizer
1: [1, 1, 1, 0] (Free: 1, money: 1, now: 1, iPhone: 0)
2: [1, 0, 1, 1] (Free: 1, money: 0, now: 1, iPhone: 1)
TfidfVectorizer
1: [0.5, 0.5, 0.5, 0.0] (Free: 0.5, money: 0.5, now: 0.5, iPhone: 0.0)
2: [0.5, 0.0, 0.5, 0.5] (Free: 0.5, money: 0.0, now: 0.5, iPhone: 0.5)
적절한 백터 라이브러리를 사용하길 바란다.
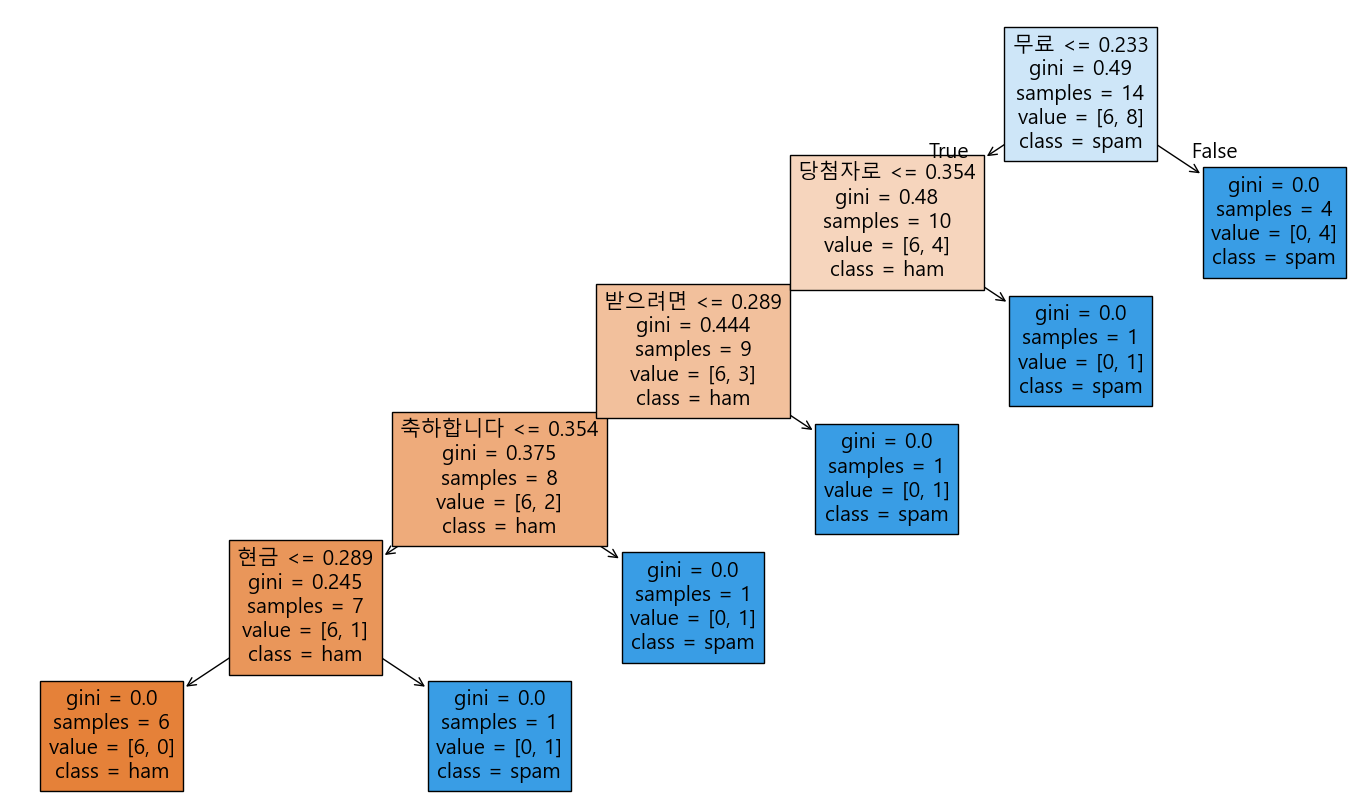
결정 트리 시각화에서 나오는 `gini`, `samples`, `value`의 의미는 다음과 같다:
1. gini: 지니 불순도(Gini impurity)를 나타낸다. 지니 불순도는 노드의 불순도를 측정하는 지표로, 값이 0에 가까울수록 노드가 순수함을 의미한다. 즉, 한 클래스의 샘플만 포함되어 있을 때 지니 불순도는 0이 된다.
2. samples: 해당 노드에 있는 샘플의 수를 나타낸다. 이 값은 해당 노드에서 분류된 데이터 포인트의 수를 의미한다.
3. value: 각 클래스에 속하는 샘플의 수를 나타낸다. 예를 들어, `value=[10, 5]`는 해당 노드에 10개의 첫 번째 클래스 샘플과 5개의 두 번째 클래스 샘플이 있음을 의미한다.
그리고 결과를 보면, 무료가 가장 먼저 나오는 것을 알 수 있다. 학습 데이터에 가장 많이 분포되어 있기 때문이다. 결정 트리는 자동적으로 가장 많은 클래스(백터)를 우선해서 결정트리가 만들어진다. 그리고 gini 값이 적을 수록 상위로 랭킹된다.
(불순도 계산식은 자신의 좌우 하위 트리 노드양를 기준으로 전체 노드를 나누어 계산하기 때문에 값이 낮을 수록 하위 노드가 많다는 의미이다.)
그리고 생각했던 트리가 너무 많아질 수 있는데, 이는 max_depth를 이용해서 조절할 수 있다. 여기에서는 3회로 조정해보도록 하자.
# Train a decision tree classifier with max_depth=3
clf = DecisionTreeClassifier(max_depth=3)마지막으로 우리가 학습시킨 결정 트리가 잘 동작하는지 확인해볼 차례이다.
평가하는 함수를 만들고 실제 테스트 데이터를 넣어서 테스트해보도록 하자.
def predict_spam(text):
text_vectorized = vectorizer.transform([text])
prediction = clf.predict(text_vectorized)
return "spam" if prediction[0] == 1 else "ham"
# Test the function with new data
new_text = "무료 쿠폰을 받으세요"
print(f"'{new_text}' is classified as: {predict_spam(new_text)}")
new_text = "안녕하세요, 내일 만날까요?"
print(f"'{new_text}' is classified as: {predict_spam(new_text)}")
결과가 잘 나온 것을 알 수 있다.
'Bigdata' 카테고리의 다른 글
| 머신러닝 - 로지스틱 회귀 분류 알고리즘 이해, 시그모이드 함수 (1) | 2024.12.28 |
|---|---|
| 머신러닝 - 데이터셋 표준화 (0) | 2024.12.27 |
| 머신러닝 - 선형 회귀 핵심 정리 (0) | 2024.12.27 |
| 회귀 알고리즘 정리 및 특징 정리, 사례 (0) | 2024.12.16 |
| LLM - Llama를 NPU 활용, 성능은 어느 정도 일까? (1) | 2024.11.01 |


