데이터셋 표준화는 모델 훈련 전에 데이터의 스케일을 조정하는 과정이다. 그리고 머신러닝 데이터들은 많은 학습을 위해서 메모리와 연산 작업을 처리하는데, 표준화를 수행하는 주요 이유는 다음과 같다.
모델 성능 향상: 많은 머신러닝 알고리즘(특히, 릿지 회귀, 로지스틱 회귀, SVM 등)은 특성의 스케일에 민감하다.
표준화를 통해 모델이 더 빠르고 안정적으로 수렴할 수 있게 된다.
특성 중요도 균형: 표준화를 통해 모든 특성이 동일한 스케일을 가지게 되면, 모델이 특정 특성에 과도하게 의존하지 않도록 할 수 있다.
수치적 안정성: 표준화를 통해 큰 값과 작은 값의 차이를 줄여 수치적 계산의 안정성을 높일 수 있다.
표준화는 일반적으로 각 특성의 평균을 0, 표준 편차를 1로 맞추는 방식으로 수행된다. 다음은 표준화를 수행하는 코드이다.
import numpy as np
from sklearn.preprocessing import StandardScaler
import matplotlib.pyplot as plt
# Example dataset
data = np.array([[1.0, 2.0, 3.0],
[4.0, 5.0, 6.0],
[7.0, 8.0, 9.0]])
# Initialize the StandardScaler
scaler = StandardScaler()
# Fit the scaler to the data and transform the data
standardized_data = scaler.fit_transform(data)
print("Original Data:\n", data)
print("Standardized Data:\n", standardized_data)
# Plotting the original and standardized data
fig, axes = plt.subplots(1, 2, figsize=(12, 6))
# Original Data
axes[0].plot(data.T)
axes[0].set_title('Original Data')
# Standardized Data
axes[1].plot(standardized_data.T)
axes[1].set_title('Standardized Data')
plt.tight_layout()
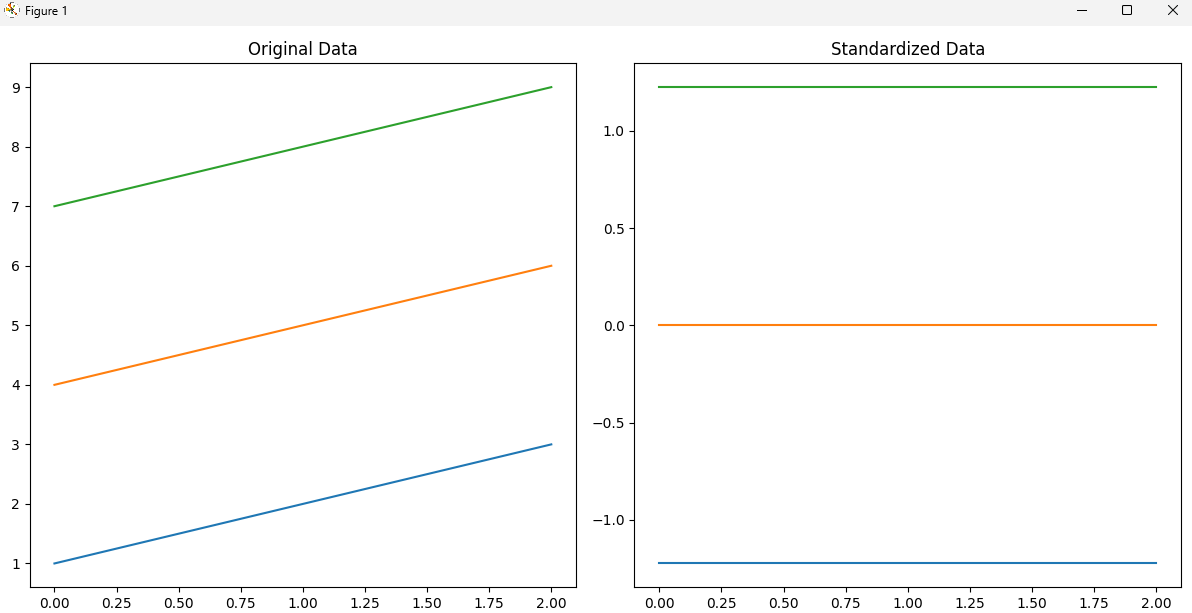
plt.show()위 코드를 실행하고 표준화 된 그래프를 보면, 3가지 값을 표현하는데, 녹색은 1, 주황색은 0 청색은 -1.0로 표준화 된것을 알 수 있다.
아래 결과는 값이 많지 않아서 값의 왜곡이 있을 수 있지만, 수십만개의 값을 표준화 할 경우에는 성능성 이점과 메모리 효율이 발생할 수 있고, 이것이 딥러닝헤서 BitsAndBytes 논문으로 나온것이라고 할 수 있다.
bitsandbytes
bitsandbytes는 모델을 8비트 및 4비트로 양자화하는 가장 쉬운 방법입니다. 8비트 양자화는 fp16의 이상치와 int8의 비이상치를 곱한 후, 비이상치 값을 fp16으로 다시 변환하고, 이들을 합산하여 fp16으
huggingface.co
'Bigdata' 카테고리의 다른 글
| 머신러닝 - 결정 트리(DecisionTree) 알고리즘 핵심 정리 (0) | 2024.12.29 |
|---|---|
| 머신러닝 - 로지스틱 회귀 분류 알고리즘 이해, 시그모이드 함수 (1) | 2024.12.28 |
| 머신러닝 - 선형 회귀 핵심 정리 (0) | 2024.12.27 |
| 회귀 알고리즘 정리 및 특징 정리, 사례 (0) | 2024.12.16 |
| LLM - Llama를 NPU 활용, 성능은 어느 정도 일까? (1) | 2024.11.01 |


